Deepseek 新论文 DualPath 的一些理解
面临问题的背景
1. Agentic工作负载的I/O密集特性
在Agentic应用场景(如编程助手、自主任务代理)中,LLM通过多轮交互与环境(如终端、Python解释器)协作,形成包含数百轮的长期会话。这种工作负载呈现长上下文、短追加、多轮次的特征:
- 极高的KV-Cache命中率

- 计算与I/O比例失衡:Cache-Compute Ratio(每PFLOP计算所需加载的KV-Cache数据量)高达数十GB,使系统性能由存储I/O而非GPU计算能力主导
2. PD分离架构中的存储网络带宽不对称饱和
现有推理系统广泛采用PD分离架构(将Prefill阶段和Decode阶段分配到不同GPU),但存在根本性的资源利用不均衡:
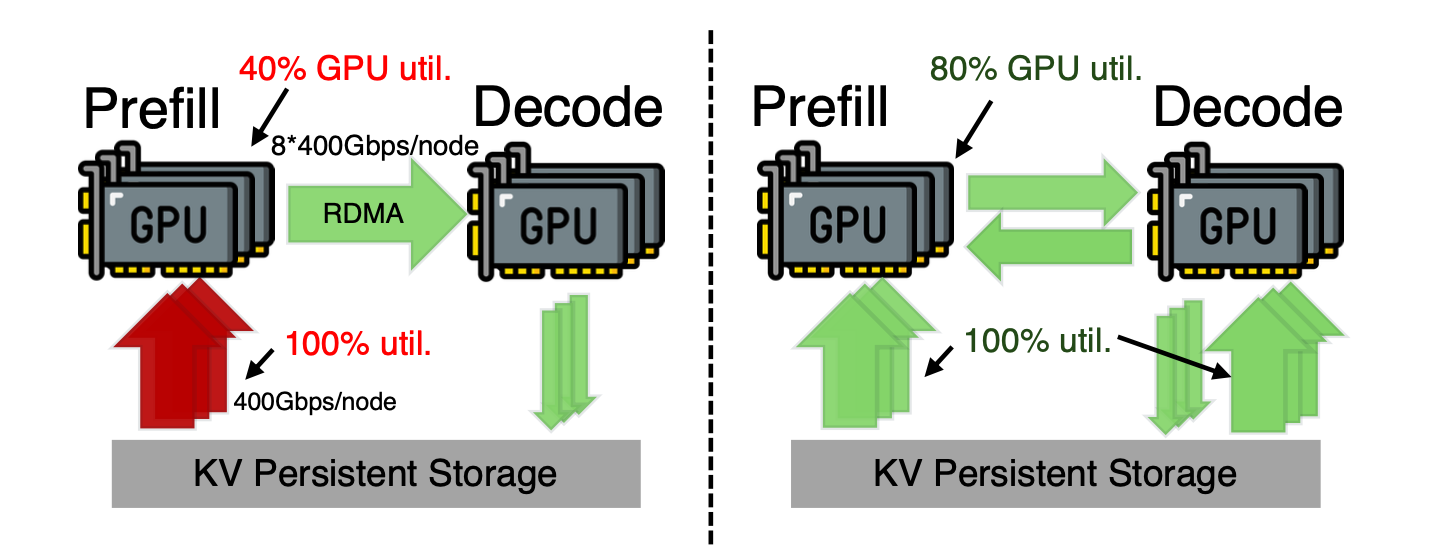
- 预填充引擎(PE)侧瓶颈:所有KV-Cache必须从外部存储加载至PE,导致PE节点的存储网卡(SNIC)带宽持续饱和(100%利用率),成为系统吞吐量瓶颈
- 解码引擎(DE)侧闲置:DE节点的存储网卡带宽几乎未被利用(接近0%利用率),形成显著的带宽资源浪费
- 硬件资源错配:尽管计算网络(CNIC)具有高带宽和间歇性流量特征,但传统架构未能利用DE节点的存储带宽和计算网络余量来加速KV-Cache加载
3. 内存墙
被人熟知的问题。

从英伟达 Ampere 到 Blackwell,I/O‑计算比率下降了 $ 28.8 / 2.0 = 14.4$。
综合以上三点,不难得出结论:
Agentic 任务的瓶颈是 KV Cache 的 I/O,而 PD 分离架构中 I/O 通道没有被填满,存在非对称的可利用空间
Related Works
PD 分离架构
将 LLM 推理请求的两个阶段分别部署在不同的机器上,使用集群内的节点间高速通信传输 KV-Cache。
Layer-wise prefill
以层为粒度管理 KV Cache 是否常驻在显存中或卸载到 DRAM/外部存储。
InfiniBand
本文基于的 I/O 系统大体有以下架构:
8卡节点为一台服务器,每张卡有一个连接到 InfiniBand 网络的 400Gbps RDMA 网络接口卡,称为 CNIC。
InfiniBand 网络包含一些交换机和高速网络,可以在不同节点的 HBM 间直接传输,同时主机 DRAM 也可以提交本地回环任务和本节点的 HBM 通信。这种通信方法和 CUDA Copy 协议不同,虽然都是 PCIE 物理链路,但是这种通信的流量可以受到 CNIC 的 QoS 调控,也就是说 CNIC 可以调控 GPU 之间通信与 HBM-DRAM 通信的优先级,而使用 CUDA Copy 则不行,会导致负责 Decoding 的节点显存带宽被抢占。
KV Cache 存储在独立的存储网络中(DeepSeek 的 3FS),每个节点额外有一个 400Gbps 的网卡连接到存储网络。
Dual Path

想要实现理想的效果,需要确保下面几点:
瓶颈在 SNIC 带宽而非 HBM/DRAM 带宽
令 \(P\) 和 \(D\) 分别表示预填充和解码节点的数量,PE 代指预填充节点,DE 代指解码节点。每个节点有 \(g\) 个GPU,每个GPU有一个带宽为 \(B\) 的 CNIC,每台机器的 SNIC 带宽为 \(s \times B\),\(M\) 是每台机器的 DRAM 带宽。

这个计算并不困难,做出合理的负载均衡假设(每个 DE gpu 向所有 PE gpu 等量地读写 KV-Cache,同一节点内的 DE gpu 等量分配 SNIC 的带宽),然后列出 DE SNIC 的带宽上限、PE SNIC 的带宽上限和 DE/PE DRAM 的带宽上限即可。
DE 侧原有的计算任务不受影响
这是一个 QoS 需求,帮助 PE 传输 KV-Cache 相比自己的解码任务是低优先级的。使用 CNIC 网卡的虚拟通道功能就可以指定不同流量的优先级,不过就像之前提到的,在 DRAM 和 DE 侧 GPU 通信时不能走 CUDA Copy 协议,必须向 CNIC 提交本地回环读写请求,让 CNIC 控制其优先级。
能在合理时间内做出调度决策
这一部分的算法不算精巧。
KV Cache 以层为单位被传输,确定 KV Cache 传输路径的算法分成两步:首先选择一个 (PE, DE) 对,然后在 PE 和 DE 中做出抉择。
为了确定 (PE,DE) 对,DeepSeek 设计了一个带有负载评估的分组调度算法,把 GPU 分组并保证组内都是 PE/DE 且同一节点的 GPU 在同一组。组内有一个组长 GPU,定时搜集组内 GPU 的负载情况,然后向调度器为整组 GPU 申请任务。
确定 PE
分配策略包括 token 数量优先级与 SNIC 负载优先级。
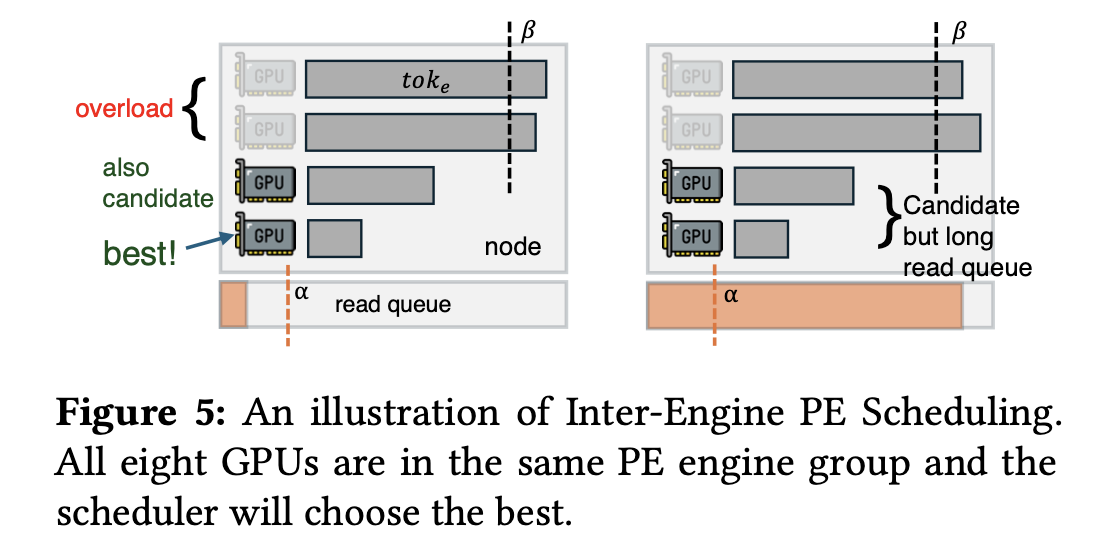
确定 DE
在组间,调度器按照 FIFO 并平衡组 token 总数的原则分配任务。
在组内,调度器按照 token 总数和请求数两级优先级分配任务,计算一个阈值 \(Z\) 为 $ 1.05 $ 组内任务 token 平均值,优先按照请求数量分配 token 数 \(<Z\) 的 GPU,再按照 token 数分配剩下的 GPU,仍遵循 FIFO 原则。
在 PE/DE 中抉择
按照所在节点的 SNIC 队列长度分配,这个选择是很敷衍的,感觉上是能用就行。敷衍的原因也很显然:PE/DE 可用的 SNIC 带宽实际是不同的。
为什么分组?
被认为是减少调度器压力和降低气泡时长,但不完全说的过去。
1.05 与请求数优先
1.05 是神秘常数。
请求数优先应该是考虑到 Decoding 的任务特点,SNIC 流量和请求数量相当。
可以看出这个算法基本处于能 work 的状态,看起来不太优雅,但是我没有实践经验,也不好评价是不是有 trade-off。
引擎内调度
这一部分和 Dual Path 没关系,是具体计算部分的调度而非传输 KV Cache 的调度。
DE 只需要加入 batch 就行了,PE 采用设定计算配额的方法,对于超出配额的 prefill 任务采取分块的策略。此方案是为了确保各 GPU 的 attention 时间相近,因为 DP/EP 策略需要 All to All 通信,所以 attention 时间不同会产生气泡。
实验
- 离线推理:吞吐量提升高达1.87×(相比基线),性能接近理想Oracle(无I/O开销)上限
- 在线服务:在不违反SLO(TTFT≤4s, TPOT≤50ms)前提下,吞吐量平均提升1.96×
- 可扩展性:在1,152 GPU规模下,48P96D配置实现近线性加速(48K代理JCT与2P4D、2K代理相当),调度器开销低于10核CPU

DualPath的TTST与Basic相当,而TPOT表明DualPath与Basic相比没有引入额外的解码开销。
SGL 基于 Mooncake 系统,要求更高的分布式 DRAM 以 KV-Cache 为中心调度,在此场景下和 DualPath 对比并不是公平的,应该说各有侧重。
消融研究(Ablation Study)
在64K MAL、1024和2048代理的离线推理设置下,逐步添加技术组件量化贡献(图12右):
| 技术组件 | 相对Basic的JCT降低 |
|---|---|
| +层-wise预填充(Layerwise) | 17.21% |
| +双路径加载(DPL) | 38.19%(累计) |
| +调度算法(Sched) | 45.62%(累计) |
负载均衡分析(图13、图14):
- 存储NIC流量:调度算法将Max/Avg流量比从1.53(轮询调度)改善至1.18
- 注意力层执行时间:任务初期(前5%)Max/Avg比低至1.06,有效减少GPU空闲气泡
further work
- 离线推理的工作负载高度动态,需要更具适应性和灵活性的并行设置和P/D比率配置方法,例如模拟器或在线调整机制
- 调度算法仍有改进空间,因为我们期望在大规模部署下实现更低的TTFT百分位数
评价
紧密结合生产的研究。“利用空闲的带宽”听上去很简单,但是不在实践中观察就无法得到这个 Idea。配套的实验很扎实,特别是技术落地上对集群体系结构的分析和处理滴水不漏,算法确实还有提高空间。